18 minutes
Building portable eBPF Programs - CO-RE

Introduction
In this post, we will learn about portable or relocatable eBPF programs. You might wonder, can we not just copy our compiled program to another machine with the same CPU architecture and run it like any other program?
Well, usually not. eBPF programs are more unique and rightfully so. They run directly in the kernel space and miss out on some of the help and abstractions that normal programs benefit from.
This is a good opportunity to demonstrate Compile Once - Run Everywhere or CO-RE to develop portable/relocatable eBPF programs by showcasing three examples:
- flat, our beloved program we developed
- tcprtt_sockops
- tcp_rtt
The last two programs are from Cilium’s eBPF GitHub repository, and they are kind of similar to flat but use different probes.
Make sure to check out the previous posts in this series.
- eBPF primer
- Setup an eBPF Development Environment
- Building an Efficient Network Flow Monitoring Tool with eBPF - Part 1
- Network Headers
- Building an Efficient Network Flow Monitoring Tool with eBPF - Part 2
- Building an Efficient Network Flow Monitoring Tool with eBPF - Part 3
The Problem
Depending on their type, most eBPF programs are inherently not portable. i.e. a program that is compiled on kernel version 5.5 might not run on kernel version 5.6.
This is due to different kernel versions shipping with different kernel headers, modified data structs and different memory layouts.
For instance fields in structs may be added, deleted, or renamed. For the sake of demonstration say, the UDP header struct for kernel version 5.5 is defined like this:
struct udphdr { /* Offset Size */
__be16 source; /* 0 2 */
__be16 dest; /* 2 2 */
__be16 len; /* 4 2 */
__sum16 check; /* 6 2 */
};
In the next kernel release, 5.6, kernel developers might decide to place these fields into a new struct or rename the dest field to destination since the field above it is the complete word. Or perhaps move these fields up or down (changing their offset):
struct udphdr { /* Offset Size */
__be16 len; /* 0 2 */
__be16 source; /* 2 2 */
__be16 destination; /* 4 2 */
__sum16 check; /* 6 2 */
};
Do you see the problem?
In our code, we might refer to specific fields/offsets, etc. which are bound to change and our eBPF program has no view or control over them.
As a result, it might read or output random garbage on different kernel versions than it was compiled on, or not run at all.
In order to tackle this problem a few years ago (pre-2020/2021), we had to:
- Install and use kernel headers plus BCC (that depends on Clang/LLVM), a resource-intensive and quite heavy piece of software (1GB+), on all our target machines. This is very inefficient and inconvenient. But, in exchange, BCC would provide this translation for us, through the use of helper functions such as
bpf_probe_read() - Or write and maintain multiple versions of the same eBPF program with conditionally specified
structaccess code and other requirements based on specific kernel versions and distros
As you might have already guessed, this is no easy task and leads to maintenance hell and bugs.
Not all eBPF programs suffer from the lack of portability. This problem does not exist for programs that only use BPF stable interfaces, or
syscalldue to their stable ABI nature. However, these programs will be quite limited in functionality, as we will see later on in this post.
The Solution - BPF CO-RE
BPF Compile Once - Run Everywhere or CO-RE, as its name suggests, enables relocatable or portable BPF bytecode, eliminating the need to write and maintain multiple versions of the same program or having to re-compile your program for each specific distro and kernel version. So, a single program can execute on various kernel versions.
Here are the components that are added or modified in order to make CO-RE a possibility:
- Kernel: Provides enhanced eBPF capabilities. For example, new BPF helper functions and map types.
- Compiler (Clang): Stores the relocation information of our program. For instance, if we access the
destfield in theudphdrstruct, Clang will record the field name, its type, and the struct to which it belongs. If the target kernel has a changed version of theudphdrstruct, it can still be found using the BTF relocation. - BPF Type Format or BTF: Provides the necessary type information so that struct offsets and other details can be queried and adjusted by the BPF loader when needed.
- BPF Loader (e.g. Cilium eBPF or libbpf): Maps
BTFfrom the target kernel and our BPF program type information together to adjust the compiled BPF program for the target kernel. We can roughly think of it as an English dictionary, you have a word and you can look up its definition.
Let’s briefly expand on BTF.
BPF Type Format (BTF)
BPF Type Format or BTF is a more efficient and compact alternative to DWARF that is the debug information or metadata describing the C data structures (e.g. struct offsets) and other details such as program’s specs and maps used in an eBPF program that can be queried as needed when the program is executed.
The BTF information can be extracted and inspected using tools like pahole and bpftool. We will see bpftool in action later.
When an eBPF program is loaded into the kernel, the BTF information is loaded along with it. If we were to read a specific field in a struct in kernel version X that changes in version Y, BTF enables libbpf (or any other BPF loader) to read that debug information, see how and where that field has changed, find it and read from there instead of what was initially specified.
One very important point to keep in mind is that the kernel of the target machine must have also been compiled and shipped with the BTF option (CONFIG_DEBUG_INFO_BTF=y) enabled. Otherwise, we need to either:
- Re-compile the kernel with the
CONFIG_DEBUG_INFO_BTF=yoption or upgrade the kernel, which is not feasible in most cases - Provide the BTF information of that specific kernel alongside our program as well, for example by using projects like BTFhub, which we explore later on.
Most common Linux distros are now built and ship with BTF option enabled. For an exhaustive list of supported kernels and distribution versions check out this page.
Does Your Kernel Ship With BTF?
To check if your Linux kernel has the CONFIG_DEBUG_INFO_BTF=y option set, you can use the following command:
TheGrayNode.io~$ grep CONFIG_DEBUG_INFO_BTF /boot/config-$(uname -r)
CONFIG_DEBUG_INFO_BTF=y
CONFIG_DEBUG_INFO_BTF_MODULES=y
You can then check to see if your kernel comes with the BTF information by running:
TheGrayNode.io~$ ls -lsh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 4.9M Dec 22 23:53 /sys/kernel/btf/vmlinux
If no output is shown for the commands above, it means the option was not set and the kernel is not exposing the vmlinux binary.
Remember that each distro and kernel version has its own specific BTF file.
vmlinux vs vmlinux.h
The BTF information within a kernel becomes accessible through the .btf section of the /sys/kernel/btf/vmlinux ELF file. The vmlinux file is the raw, statically linked Linux kernel image. It contains the executable code of the Linux kernel in a format that can be directly loaded into memory and executed by the computer’s hardware. The name vmlinux is derived from virtual memory linux.
The vmlinux file can be utilized to generate a header file that is conventionally named vmlinux.h from the running kernel. This header file includes all internal kernel types and data structure information that a BPF program may require.
It is worth noting that the generated header file, similar to DWARF, lacks the #define macros, but this is not a significant issue since we can provide those ourselves. For instance:
- bpf_helpers that comes with
libpbf - Or Tracee’s approach.
Leveraging the bpftool, we can easily generate the vmlinux.h header file:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Then, we can place it where the eBPF code is, in our case, the bpf folder and include it in the code. This is great since we do not need to install so many different header files anymore.
To put it into perspective, for flat, all these imports:
#include <stdbool.h>
#include <stdint.h>
#include <stdlib.h>
#include <linux/bpf.h>
#include <linux/bpf_common.h>
#include <linux/if_ether.h>
#include <linux/if_packet.h>
#include <linux/in.h>
#include <linux/in6.h>
#include <linux/ip.h>
#include <linux/ipv6.h>
#include <linux/tcp.h>
#include <linux/udp.h>
#include <linux/pkt_cls.h>
Get replaced with a single line:
#include "vmlinux.h"
Pretty neat!
Anyway, let’s roll-up our sleeves and use it in action.
First Example - flat
As mentioned in the previous post, flat uses the __sk_buff struct that is specifically designed to work with eBPF and is stable across different kernel versions. In other words, without making any changes and re-compilation, it is already portable/relocatable and runs across a variety of kernel versions.
Let’s pick an old kernel and run it there.
Looking at BTFhub, we can see Ubuntu 18.04 with kernel 4.15.0 supports BPF but does not ship with BTF, which makes it the perfect match for our test.
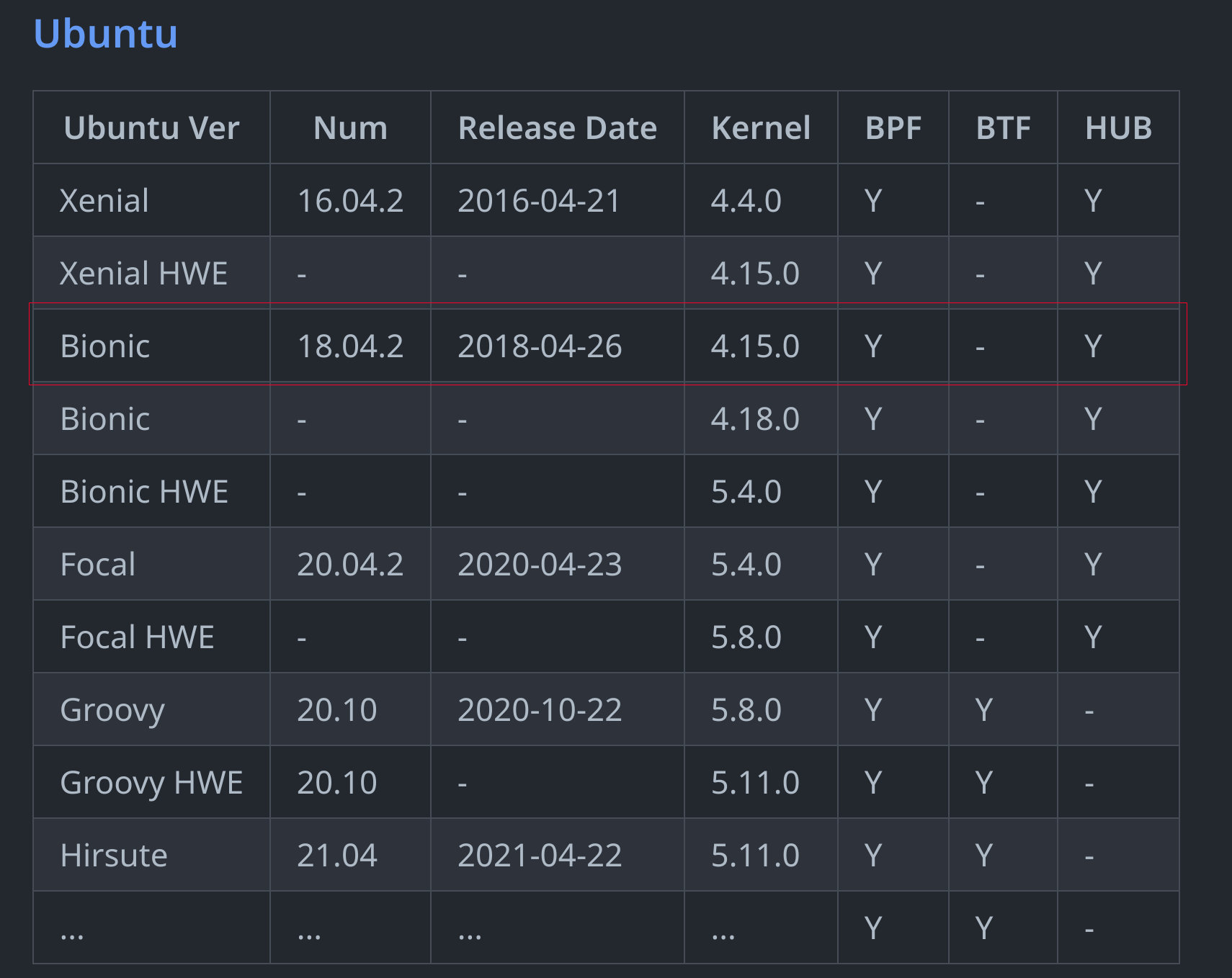
Moment of truth:
TheGrayNode.io@kernel_4.15.0~$ sudo ./flat -i eth0
[...]
map create: invalid argument (without BTF k/v)
Huh? map create? What happened here?
Well, it turns out, this is because of the ringbuf map type, which is added in kernel 5.8 onwards (thank you Mauricio, for helping with this).
Luckily, the fix for this is pretty simple. We can switch to the perfbuf map type at the price of a little less performance. Just remember that the map type in our user space program also needs to change.
A revert of this commit contains all the necessary changes to enable it to run on kernels as old as 4.15.0 (possibly, even older).
flat successfully runs on kernel 5.8 and newer without requiring any changes to the original program.
To make it a bit more convenient, here, I have added a separate file named flat_portable.c, showing the use of vmlinux.h header file and the perfbuf map type.
This was easy. Let’s move onto a bit more challenging scenario.
Second Example - tcprtt_sockops
The tcprtt_sockops program inside the examples folder of Cilium’s eBPF repository, works kind of similar to flat but uses the sockops program type instead of tc and attaches to the cgroupv2 hook.
The internals and the way this program works are not really important for us. We just want it to be portable.
For this example, I have decided to use Ubuntu 20.04 with kernel 5.8.0 which supports the
ringbufmap type.
Let’s run the program as is, and see what happens anyway:
TheGrayNode.io@kernel_5.8.0~$ sudo go run main.go
[...]
[...] program bpf_sockops_cb: apply CO-RE relocations: load kernel spec: \
no BTF found for kernel version 5.8.0-63-generic: not supported
Well, the error message is pretty self-explanatory. How do we go about fixing this?
Remember that we had two options:
- Re-compile the kernel with the
CONFIG_DEBUG_INFO_BTF=yoption set or upgrade to a newer kernel version - Use a project like BTFhub that offers BTF files for various kernels and distros
Re-compiling a kernel is time-consuming, inconvenient, and requires a lot of extra work, especially if the target machine is in production, ultimately making it a no-go.
The second option is very pragmatic and in fact many projects such as Tracee and Inspektor Gadget rely on this approach.
Thankfully, BTFhub has a BTF file for kernel version 5.8.0.
BTFhub
This is how BTFhub defines itself:
BTFhub, in collaboration with the BTFhub Archive repository, supplies BTF files for all published kernels that lack native support for embedded BTF. This joint effort ensures that even kernels without built-in BTF support can effectively leverage the benefits of eBPF programs, promoting compatibility across various kernel versions
The btfhub application accomplishes this by downloading all existing debug kernel packages for the supported distributions and then converting the embedded DWARF information into BTF format.
Let’s get the BTF file of our distro and its kernel version from the BTFhub Archive repository and extract it.
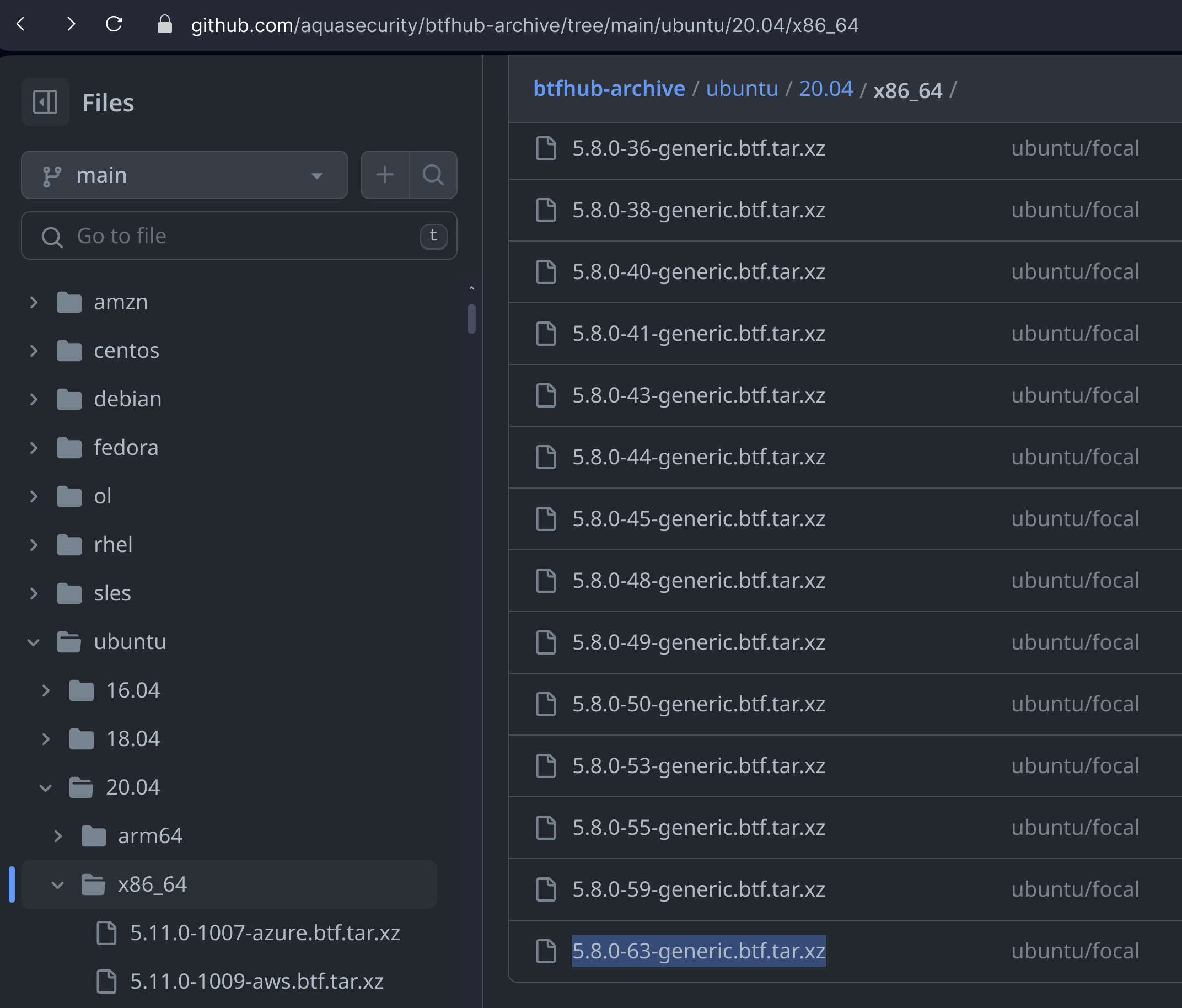
If you prefer using the CLI, I got you:
wget https://github.com/aquasecurity/btfhub-archive/blob/main/ubuntu/20.04/x86_64/5.8.0-63-generic.btf.tar.xz && \
tar -xvf 5.8.0-63-generic.btf.tar.xz
This will give us a file named 5.8.0-63-generic.btf.
Processing BTF Files
Ok, now that we have our BTF file, let’s see how we can use it.
First off, in our user space program, we need to check if the vmlinux binary on the machine running the program is exposed. If not, we can fetch the distro and kernel version of the machine, look for its BTF file and pass it to the BPF loader.
In case you missed it, the key term here is, look for its BTF file. But where?
- One option is to ship the BTF files for various kernels alongside our binary and refer to them in our user space program. This is error-prone and undesirable since we have to ship hundreds (possibly thousands) of files with our program.
- The other option is to take advantage of Go’s embed feature and include all our BTF files inside our main program; a single binary that contains everything.
However, wouldn’t both of these approaches significantly increase the size of our program? They absolutely would.
For instance, the 5.8.0-63-generic.btf file alone is almost 5MBs. What more if we want to support as many kernels and distros out there as possible?
Fortunately, the bpftool (my version is v7.3.0) now includes BTFGen, which, given a BTF file, analyzes our BPF bytecode, captures the actual types in use, and then tailors down or minifies the original BTF file.
In order to generate a minified version of 5.8.0-63-generic.btf BTF file, run:
bpftool gen min_core_btf 5.8.0-63-generic.btf btfs/5.8.0-63-generic_min.btf tcprtt_bpfel.o
Notice that we are passing the original BTF file as the first argument, the path and name of the minified version as the second one, and lastly, the name of the BPF bytecode (tcprtt_bpfel.o) to be analyzed. Of course, we need to compile our eBPF program first for the bpftool to be able to analyze it.
Let’s compare the size of these two files:
TheGrayNode.io@kernel_5.8.0~$ ls -lsh
4.9M 5.8.0-63-generic.btf
328 5.8.0-63-generic_min.btf
From almost 5MBs to only 328 bytes. That is some serious reduction, allowing us to embed a lot of BTF files in our program to support a broader landscape.
Making tcprtt_sockops Portable
Here are the required steps to make the original tcprtt_sockops program portable:
- Create a
bpffolder to contain our kernel space code andvmlinux.hheader file (otherwisebpf2gocomplains about user and kernel space programs being in the same place). - Create a
btfsfolder to contain our BTF files and theembedlogic. - Pass the
-gflag to Clang usingbpf2goto generate the debug information - Check the kernel to see if it has exposed the
vmlinux, and if not, load a BTF file specific to the running kernel version.
Now, let’s dive into the details of each step.
Embed BTF Files
Here, we create the btfs folder, then the btfs.go file, and transfer our BTF files there; in our case only the 5.8.0-63-generic_min.btf file.
These four lines are all that is needed in btfs.go:
package btfs
import "embed"
//go:embed *.btf
var BtfFiles embed.FS
- We name the package
btfs - Import the
embedpackage - Include all the files ending with
.btfin the same folder as ourbtfs.gofile, using the//go:embed *.btfdirective - This gives us an embedded filesystem named
BtfFiles, that can be accessed later on.
Let’s have a look at how these files could be accessed from our user space code.
Access Embedded BTF Files
Accessing our embedded BTF files from the user space program is pretty simple.
- We first try to look for and use the
vmlinuxfile throughbtf.LoadKernelSpecfunction, and if the file is not present, - Utilize the
btfspackage, reach into our embedded filesystem,BtfFiles. Call the ReadFile function, which returns the contents as a[]byte - Convert those bytes into a Reader by using
bytes.NewReader. This conversion allowsbtf.LoadSpecFromReaderto use the data - Finally, load the program into the kernel, passing the BTF as a program option to the
KernelTypesfield in theebpf.CollectionOptions.
import (
// existing imports
_ "embed" // blank import for embed side effects
)
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go tcprtt ./bpf/tcprtt_sockops.c - clang-14 -O2 -g -Wall -Werror -Wno-address-of-packed-member -- -I ./bpf/vmlinux.h
// -I flag is a way to provide the path to our Linux headers, in this case ./bpf/vmlinux.h
// Get the kernel version and distro
func getKernelVersion() string {
// finding the kernel version and distro logic
return "5.8.0-63-generic"
}
func main() {
// previous code
var btfSpec *btf.Spec
// Here we check the existence of vmlinux file
btfSpec, err = btf.LoadKernelSpec()
if err != nil {
// If vmlinux does not exist, we load our own BTF file
kernelVersion := getKernelVersion()
btfFileName := fmt.Sprintf("%s_min.btf", kernelVersion)
btfFileReader, err := btfs.BtfFiles.ReadFile(btfFileName)
if err != nil {
log.Fatalf("Failed reading %v BTF file %v", btfFileReader, err)
}
log.Printf("Opened %s\n", btfFileName)
// Convert the []byte to Reader
btfSpec, err = btf.LoadSpecFromReader(bytes.NewReader(btfFileReader))
if err != nil {
log.Fatalf("Failed creating BTF handle: %v", err)
}
} else {
log.Println("Kernel is shiped with BTF")
}
objs := tcprttObjects{}
// Load the program and pass it the BTF information
if err := loadTcprttObjects(&objs, &ebpf.CollectionOptions{
Programs: ebpf.ProgramOptions{
KernelTypes: btfSpec,
},
}); err != nil {
log.Fatalf("loading objects: %v", err)
}
// rest of the code
}
Generate the eBPF bytecode and compile the program:
TheGrayNode.io@kernel_5.8.0~$ go generate ./... && \
CGO_ENABLED=0 go build -ldflags "-s -w" -o tcprtt_sockops
That is all. This program successfully runs on our Ubuntu 20.04 with kernel 5.8.0 now.
TheGrayNode.io@kernel_5.8.0~$ sudo ./tcprtt_sockops
2023/12/22 23:01:21 Opened 5.8.0-63-generic_min.btf
2023/12/22 23:01:21 eBPF program loaded and attached on cgroup /sys/fs/cgroup/unified
2023/12/22 23:01:21 Src addr Port -> Dest addr Port RTT (ms)
2023/12/22 23:01:27 192.168.122.210 33890 -> 94.124.216.34 80 108
2023/12/22 23:01:27 192.168.122.210 53 -> 9.9.9.9 53 23
If you are curious to see how bigger projects that support a wide variety of kernels and distros out there tackle portability issues, you can have a look at Inspektor Gadget’s approach here as well as Tracee’s using this link.
The Finalized Program
This is how the folder structure should ultimately look like:
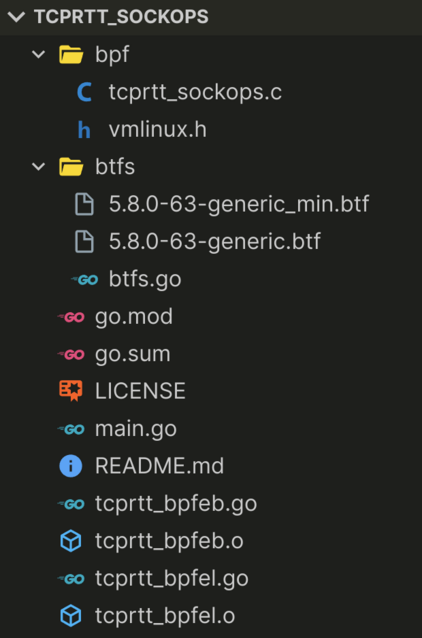
I have included both the original and the minified version of our BTF file there; however, only the minified version is needed.
Here is the link to the CO-RE version of tcprtt_sockops for kernel version 5.8.0, on GitHub:
https://github.com/pouriyajamshidi/tcprtt_sockops
As an exercise, you can add the support for other kernels and distros for yourself, test it out and even open a pull request.
Third Example - tcprtt
In order to not make this post longer than it already is, for this one, I just explain the high-level stuff and avoid repeating the steps we performed in the previous examples. Thankfully, the code is already very well documented.
tcprtt uses
fentry, also known as BPF Trampoline, which allows direct memory reads.BPF Trampolineis relatively a bit newer than other BPF program types.
Kernel Space Program
Inside the kernel space program, the author has decided not to use the vmlinux.h header file and only defined the structs and fields that the program actually needs:
struct sock_common {
union {
struct {
__be32 skc_daddr;
__be32 skc_rcv_saddr;
};
};
union {
struct {
__be16 skc_dport;
__u16 skc_num;
};
};
short unsigned int skc_family;
} __attribute__((preserve_access_index));
struct sock {
struct sock_common __sk_common;
} __attribute__((preserve_access_index));
struct tcp_sock {
u32 srtt_us;
} __attribute__((preserve_access_index));
Did you notice the attribute that follows every struct here?
The __attribute__((preserve_access_index)) attribute, preserves memory access patterns, and all direct memory reads will be automatically CO-RE relocatable.
The next interesting part is the BPF_PROG macro:
SEC("fentry/tcp_close")
int BPF_PROG(tcp_close, struct sock* sk) {
//...
}
The BPF_PROG macro is used with BPF-enabled programs like fentry, fexit, fmod_ret, tp_btf, lsm, and others, to serve as a convenience wrapper for accepting input arguments as a single pointer to an untyped u64 array, where each u64 can act as a typed pointer or differently sized integer.
This macro allows users to declare named and typed input arguments in the same syntax as a standard C function, eliminating the need for manual casting and array element indexing. Furthermore, it enables these programs to read kernel memory without using bpf_probe_read*().
The original raw context argument, as well as the ctx argument, is preserved, which is beneficial when using BPF helpers (e.g. bpf_ringbuf_output) that expect the original context as one of the parameters.
User Space Program
No changes are required for the user space program. Since, kernels that support BPF Trampoline program type already ship with BTF information.
In other words, this program type is incompatible with older kernels and is better suited to newer kernels, 5.8+.
Is That All?
By no means. CO-RE and writing portable BPF programs are a very big topic.
For instance, there are a lot of helper functions and macros like BPF_CORE_READ, and bpf_core_read to help us write portable BPF programs. And yes, those macros read the same but are different 🙃.
At this point, I do not have a project that could showcase these. Perhaps a topic for a future post?
If you are curious to find out more, definitely check the references, especially nakryiko’s blog which goes into much greater details.
What Happens to BCC?

Many programs that are utilizing BCC are either already migrated or migrating to libbpf CO-RE.
As Brendan Gregg put it in 2020, “Coding performance tools in BCC Python is now considered deprecated as we move to libbpf C with BTF and CO-RE”.
Judging by the activity on the BCC repository, we can see it is still quite active and this is not a surprise. However, its usage should slow down as BPF CO-RE becomes more widely adopted.
Conclusion
In this series, we learned how to efficiently intercept network packets using eBPF and tc hook, encode and decode information between C and Go programs, leverage the ringbuf eBPF map to calculate and display network flow latencies, as well as making flat and sockops_rtt programs portable across different kernel versions leveraging CO-RE.
I hope these posts have been useful and informative for you and thanks for reading.
Stay tuned for future posts on some of the exciting projects that I am working on.
References
- BPF CO-RE (Compile Once – Run Everywhere)
- BPF CO-RE reference guide
- BCC to libbpf conversion guide
- BPF Type Format (BTF)
- BPF binaries: BTF, CO-RE, and the future of BPF perf tools
- How Tracee solves the lack of BTF information
- What is vmlinux.h?
- libbpf
- BPF helper functions
- BPF features by kernel version
eBPF BPF Network Linux Kernel Programming Tutorial Flow monitoring Golang flat CO-RE
3730 Words
2023-12-22 09:23